Hồi quy tuyến tính là phép hồi quy xem xét mối quan hệ tuyến tính – dạng quan hệ đường thẳng giữa biến độc lập với biến phụ thuộc.
1. Lý thuyết hồi quy tuyến tính
Trong nghiên cứu, chúng ta thường phải kiểm định các giả thuyết về mối quan hệ giữa hai hay nhiều biến, trong đó có một biến phụ thuộc và một hay nhiều biến độc lập. Nếu chỉ có một biến độc lập, mô hình được gọi là mô hình hồi quy đơn biến SLR (Simple Linear Regression). Trường hợp có từ hai biến độc lập trở lên, mô hình được gọi là hồi quy bội MLR (Multiple Linear Regression). Những nội dung tiếp theo ở tài liệu này chỉ đề cập đến hồi quy bội, hồi quy đơn biến tính chất tương tự với hồi quy bội.
– Phương trình hồi quy đơn biến: Y = β0 + β1X + e
– Phương trình hồi quy bội: Y = β0 + β1X1 + β2X2 + … + βnXn + e
Trong đó:
- Y: biến phụ thuộc, là biến chịu tác động của biến khác.
- X, X1, X2, Xn: biến độc lập, là biến tác động lên biến khác.
- β0: hằng số hồi quy, hay còn được gọi là hệ số chặn. Đây là chỉ số nói lên giá trị của Y sẽ là bao nhiêu nếu tất cả X cùng bằng 0. Nói cách khác, chỉ số này cho chúng ta biết giá trị của Y là bao nhiêu nếu không có các X. Khi biểu diễn trên đồ thị Oxy, β0 là điểm trên trục Oy mà đường hồi quy cắt qua.
- β1, β2, βn: hệ số hồi quy, hay còn được gọi là hệ số góc. Chỉ số này cho chúng ta biết về mức thay đổi của Y gây ra bởi X tương ứng. Nói cách khác, chỉ số này nói lên có bao nhiêu đơn vị Y sẽ thay đổi nếu X tăng hoặc giảm một đơn vị.
- e: sai số. Chỉ số này càng lớn càng khiến cho khả năng dự đoán của hồi quy trở nên kém chính xác hơn hoặc sai lệch nhiều hơn so với thực tế. Sai số trong hồi quy tổng thể hay phần dư trong hồi quy mẫu đại diện cho hai giá trị, một là các biến độc lập ngoài mô hình, hai là các sai số ngẫu nhiên.
Trong thống kê, vấn đề chúng ta muốn đánh giá là các thông tin của tổng thể. Tuy nhiên vì tổng thể quá lớn, chúng ta không thể có được các thông tin này. Vì vậy, chúng ta dùng thông tin của mẫu nghiên cứu để ước lượng hoặc kiểm định thông tin của tổng thể. Với hồi quy tuyến tính cũng như vậy, các hệ số hồi quy tổng thể như β1, β2 … hay hằng số hồi quy β0 là những tham số chúng ta muốn biết nhưng không thể đo lường được. Do đó, chúng ta sẽ sử dụng tham số tương ứng từ mẫu để ước lượng và từ đó suy diễn ra tổng thể. Phương trình hồi quy trên mẫu nghiên cứu:
Y = B0 + B1X1 + B2X2 + … + BnXn + ε
Trong đó:
- Y: biến phụ thuộc
- X, X1, X2, Xn: biến độc lập
- B0: hằng số hồi quy
- B1, B2, Bn: hệ số hồi quy
- ε: phần dư
Tất cả các nội dung hồi quy tiếp sau đây chỉ nói về hồi quy trên tập dữ liệu mẫu. Do vậy, thuật ngữ sai số sẽ không được đề cập mà chỉ nói về phần dư.
2. Ước lượng hồi quy tuyến tính bằng OLS
Một trong các phương pháp ước lượng hồi quy tuyến tính phổ biến là bình phương nhỏ nhất OLS (Ordinary Least Squares).
Với tổng thể, sai số (error) ký hiệu là e, còn trong mẫu nghiên cứu sai số lúc này được gọi là phần dư (residual) và được ký hiệu là ε. Biến thiên phần dư được tính bằng tổng bình phương tất cả các phần dư cộng lại.
Nguyên tắc của phương pháp hồi quy OLS là làm cho biến thiên phần dư này trong phép hồi quy là nhỏ nhất. Khi biểu diễn trên mặt phẳng Oxy, đường hồi quy OLS là một đường thẳng đi qua đám đông các điểm dữ liệu mà ở đó, khoảng cách từ các điểm dữ liệu (trị tuyệt đối của ε) đến đường hồi quy là ngắn nhất.
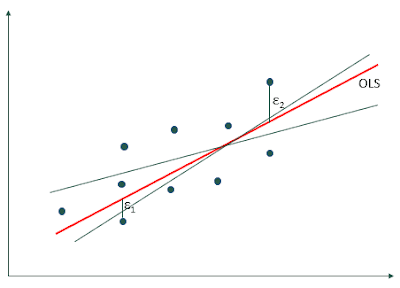
Từ đồ thị scatter biểu diễn mối quan hệ giữa các biến độc lập và biến phụ thuộc, các điểm dữ liệu sẽ nằm phân tán nhưng có xu hướng chung tạo thành dạng một đường thẳng. Chúng ta có thể có rất nhiều đường đường thẳng hồi quy đi qua đám đông các điểm dữ liệu này chứ không phải chỉ một đường duy nhất, vấn đề là ta phải chọn ra đường thẳng nào mô tả sát nhất xu hướng dữ liệu. Bình phương nhỏ nhất OLS sẽ tìm ra đường thẳng đó dựa trên nguyên tắc cực tiểu hóa khoảng cách từ các điểm dữ liệu đến đường thẳng. Trong hình ở trên đường màu đỏ là đường hồi quy OLS.
3. Phân tích hồi quy tuyến tính bội trên SPSS
Thực hiện phân tích hồi quy tuyến tính bội để đánh giá sự tác động của các biến độc lập này lên biến phụ thuộc. Chúng ta vào Analyze > Regression > Linear…
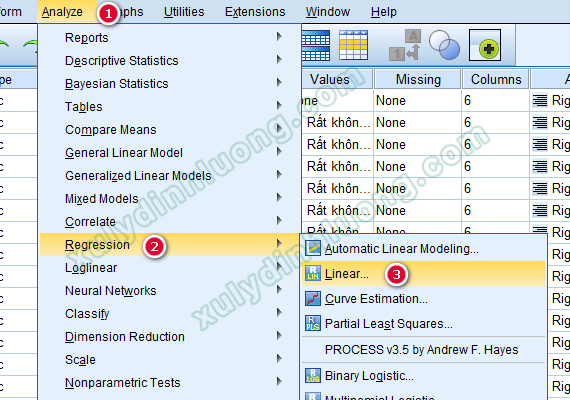
Đưa biến phụ thuộc vào ô Dependent, các biến độc lập vào ô Independents.
Vào mục Statistics, tích chọn các mục như trong ảnh và chọn Continue.
Vào mục Plots, tích chọn vào Histogram và Normal probability plot, kéo biến ZRESID thả vào ô Y, kéo biến ZPRED thả vào ô X như hình bên dưới. Tiếp tục chọn Continue.
Các mục còn lại chúng ta sẽ để mặc định. Quay lại giao diện ban đầu, mục Method là các phương pháp đưa biến vào, tùy vào dạng nghiên cứu mà chúng ta sẽ chọn Enter hoặc Stepwise. Tính chất đề tài thực hành là nghiên cứu khẳng định, do vậy tác giả sẽ chọn phương pháp Enter đưa biến vào một lượt. Tiếp tục nhấp vào OK.
SPSS sẽ xuất ra rất nhiều bảng, chúng ta sẽ tập trung vào các bảng ANOVA, Model Summary, Coefficients và ba biểu đồ Histogram, Normal P-P Plot, Scatter Plot.
3.1 Bảng ANOVA
Chúng ta cần đánh giá độ phù hợp mô hình một cách chính xác qua kiểm định giả thuyết. Để kiểm định độ phù hợp mô hình hồi quy, chúng ta đặt giả thuyết H0: R2 = 0. Phép kiểm định F được sử dụng để kiểm định giả thuyết này. Kết quả kiểm định:
- Sig < 0.05: Bác bỏ giả thuyết H0, nghĩa là R2 ≠ 0 một cách có ý nghĩa thống kê, mô hình hồi quy là phù hợp.
- Sig > 0.05: Chấp nhận giả thuyết H0, nghĩa là R2 = 0 một cách có ý nghĩa thống kê, mô hình hồi quy không phù hợp.
Trong SPSS, các số liệu của kiểm định F được lấy từ bảng phân tích phương sai ANOVA.
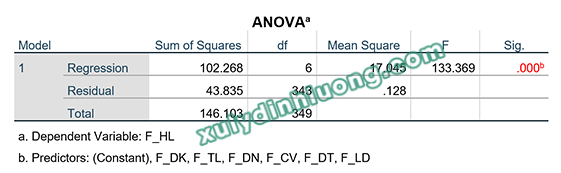
Bảng ANOVA cho chúng ta kết quả kiểm định F để đánh giá giả thuyết sự phù hợp của mô hình hồi quy. Giá trị sig kiểm định F bằng 0.000 < 0.05, do đó, mô hình hồi quy là phù hợp.
3.2 Bảng Model Summary
Các điểm dữ liệu luôn phân tán và có xu hướng tạo thành dạng một đường thẳng chứ không phải là một đường thẳng hoàn toàn. Do đó, hầu như không có đường thẳng nào có thể đi qua toàn bộ tất cả các điểm dữ liệu, luôn có sự sai lệch giữa các giá trị ước tính và các giá trị thực tế. Chúng ta sẽ cần tính toán được mức độ sai lệch đó cũng như mức độ phù hợp của mô hình hồi quy tuyến tính với tập dữ liệu.
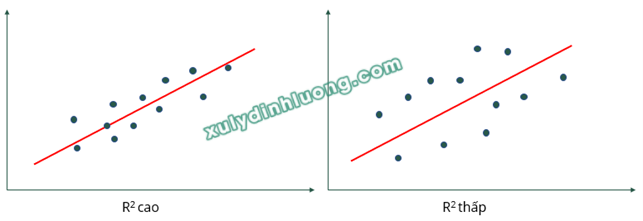
(Bên trái là độ phù hợp mô hình cao, bên phải là độ phù hợp mô hình thấp)
Một thước đo sự phù hợp của mô hình hồi quy tuyến tính thường dùng là hệ số xác định R2 (R square). Khi phần lớn các điểm dữ liệu tập trung sát vào đường hồi quy, giá trị R2 sẽ cao, ngược lại, nếu các điểm dữ liệu phân bố rải rác cách xa đường hồi quy, R2 sẽ thấp. Chỉ số R2 nằm trong bảng Model Summary.

Khi chúng ta đưa thêm biến độc lập vào phân tích hồi quy, R2 có xu hướng tăng lên. Điều này dẫn đến một số trường hợp mức độ phù hợp của mô hình hồi quy bị thổi phồng khi chúng ta đưa vào các biến độc lập giải thích rất yếu hoặc không giải thích cho biến phụ thuộc. Trong SPSS, bên cạnh chỉ số R2, chúng ta còn có thêm chỉ số R2 Adjusted (R2 hiệu chỉnh). Chỉ số R2 hiệu chỉnh không nhất thiết tăng lên khi nhiều biến độc lập được thêm vào hồi quy, do đó R2 hiệu chỉnh phản ánh độ phù hợp của mô hình chính xác hơn hệ số R2.
R2 hay R2 hiệu chỉnh đều có mức dao động trong đoạn từ 0 đến 1. Nếu R2 càng tiến về 1, các biến độc lập giải thích càng nhiều cho biến phụ thuộc, và ngược lại, R2 càng tiến về 0, các biến độc lập giải thích càng ít cho biến phụ thuộc.
Không có tiêu chuẩn chính xác R2 ở mức bao nhiêu thì mô hình mới đạt yêu cầu. Cần lưu ý rằng, không phải luôn luôn một mô hình hồi quy có R2 cao thì nghiên cứu có giá trị cao, mô hình có R2 thấp thì nghiên cứu đó có giá trị thấp, độ phù hợp mô hình hồi quy không có mối quan hệ nhân quả với giá trị của bài nghiên cứu. Trong nghiên cứu lặp lại, chúng ta thường chọn mức trung gian là 0.5 để phân ra 2 nhánh ý nghĩa mạnh/ý nghĩa yếu và kỳ vọng từ 0.5 đến 1 thì mô hình là tốt, bé hơn 0.5 là mô hình chưa tốt. Tuy nhiên, điều này không thực sự chính xác bởi việc đánh giá giá trị R2 sẽ phụ thuộc rất nhiều vào các yếu tố như lĩnh vực nghiên cứu, tính chất nghiên cứu, cỡ mẫu, số lượng biến tham gia hồi quy, kết quả các chỉ số khác của phép hồi quy,…
Trong ví dụ ở trên, bảng Model Summary cho chúng ta kết quả R bình phương (R Square) và R bình phương hiệu chỉnh (Adjusted R Square) để đánh giá mức độ phù hợp của mô hình. Giá trị R bình phương hiệu chỉnh bằng 0.695 cho thấy các biến độc lập đưa vào phân tích hồi quy ảnh hưởng 69.5% sự biến thiên của biến phụ thuộc, còn lại 31.4% là do các biến ngoài mô hình và sai số ngẫu nhiên.
Kết quả bảng này cũng đưa ra giá trị Durbin–Watson để đánh giá hiện tượng tự tương quan chuỗi bậc nhất. Giá trị DW = 1.849, nằm trong khoảng 1.5 đến 2.5 nên kết quả không vi phạm giả định tự tương quan chuỗi bậc nhất (Yahua Qiao, 2011).
3.3 Bảng Coefficients
Chúng ta sẽ đánh giá hệ số hồi quy của mỗi biến độc lập có ý nghĩa trong mô hình hay không dựa vào kiểm định t (student) với giả thuyết H0: Hệ số hồi quy của biến độc lập Xi bằng 0. Mô hình hồi quy có bao nhiêu biến độc lập, chúng ta sẽ đi kiểm tra bấy nhiêu giả thuyết H0. Kết quả kiểm định:
- Sig < 0.05: Bác bỏ giả thuyết H0, nghĩa là hệ số hồi quy của biến Xi khác 0 một cách có ý nghĩa thống kê, biến X1 có tác động lên biến phụ thuộc.
- Sig > 0.05: Chấp nhận giả thuyết H0, nghĩa là hệ số hồi quy của biến Xi bằng 0 một cách có ý nghĩa thống kê, biến Xi không tác động lên biến phụ thuộc.
Trong hồi quy, thường chúng ta sẽ có hai hệ số hồi quy: chưa chuẩn hóa (trong SPSS gọi là B) và đã chuẩn hóa (trong SPSS gọi là Beta). Mỗi hệ số hồi quy này có vai trò khác nhau trong việc diễn giải hàm ý quản trị của mô hình hồi quy. Để hiểu khi nào dùng phương trình hồi quy nào, bạn có thể xem bài viết Sự khác nhau giữa hệ số hồi quy chuẩn hóa và chưa chuẩn hóa.
Nếu hệ số hồi quy (B hoặc Beta) mang dấu âm, nghĩa là biến độc lập đó tác động nghịch chiều lên biến phụ thuộc. Ngược lại nếu B hoặc Beta không có dấu (dấu dương), nghĩa là biến độc lập tác động thuận chiều lên biến phụ thuộc. Khi xem xét mức độ tác động giữa các biến độc lập lên biến phụ thuộc, chúng ta sẽ dựa vào trị tuyệt đối hệ số Beta, trị tuyệt đối Beta càng lớn, biến độc lập tác động càng mạnh lên biến phụ thuộc. Xem chi tiết hơn tại bài viết Hệ số hồi quy B, Beta âm trong phân tích SPSS.
Trong SPSS, các số liệu của kiểm định t được lấy từ bảng hệ số hồi quy Coefficients. Cũng lưu ý rằng, nếu một biến độc lập không có ý nghĩa thống kê trong kết quả hồi quy, chúng ta sẽ kết luận biến độc lập đó không có sự tác động lên biến phụ thuộc mà không cần thực hiện loại biến và phân tích lại hồi quy.
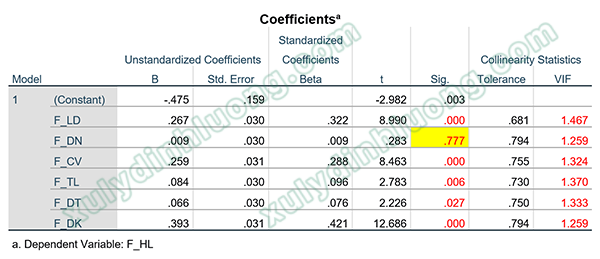
Trong ví dụ ở trên, bảng Coefficients cho chúng ta kết quả kiểm định t để đánh giá giả thuyết ý nghĩa hệ số hồi quy, chỉ số VIF đánh giá đa cộng tuyến và các hệ số hồi quy.
Biến F_DN có giá trị sig kiểm định t bằng 0.777 > 0.05 , do đó biến này không có ý nghĩa trong mô hình hồi quy, hay nói cách khác, biến này không có sự tác động lên biến phụ thuộc F_HL. Các biến còn lại gồm F_LD, F_CV, F_TL, F_DT, F_DK đều có sig kiểm định t nhỏ hơn 0.05, do đó các biến này đều có ý nghĩa thống kê, đều tác động lên biến phụ thuộc F_HL. Hệ số hồi quy các biến độc lập này đều mang dấu dương, như vậy các biến độc lập có tác động thuận chiều lên biến phụ thuộc.
Lưu ý rằng, biến không có ý nghĩa trong hồi quy thì không loại biến đó và chạy lại phân tích, lý do vì sao bạn xem chi tiết tại bài viết Biến không có ý nghĩa ở hồi quy, SEM có cần loại chạy lại không?.
Kết luận giả thuyết:
H1: Tiền lương (F_TN)tác động đến sự hài lòng của nhân viên trong công việc (Chấp nhận)
H2: Đào tạo và thăng tiến (F_DT) tác động đến sự hài lòng của nhân viên trong công việc (Chấp nhận)
H3: Lãnh đạo (F_LD) tác động đến sự hài lòng của nhân viên trong công việc (Chấp nhận)
H4: Đồng nghiệp (F_DN) tác động đến sự hài lòng của nhân viên trong công việc (Bác bỏ)
H5: Bản chất công việc (F_DN) đến sự hài lòng của nhân viên trong công việc (Chấp nhận)
H6: Điều kiện làm việc (F_DK) tác động đến sự hài lòng của nhân viên trong công việc (Chấp nhận)
Hệ số phóng đại phương sai (VIF) là một chỉ số đánh giá hiện tượng cộng tuyến trong mô hình hồi quy. VIF càng nhỏ, càng ít khả năng xảy ra đa cộng tuyến. Hair và cộng sự (2009) cho rằng, ngưỡng VIF từ 10 trở lên sẽ xảy ra đa cộng tuyến mạnh. Nhà nghiên cứu nên cố gắng để VIF ở mức thấp nhất có thể, bởi thậm chí ở mức VIF bằng 5, bằng 3 đã có thể xảy ra đa cộng tuyến nghiêm trọng. Theo Nguyễn Đình Thọ (2010) , trên thực tế, nếu VIF > 2, chúng ta cần cẩn thận bởi vì đã có thể xảy ra sự đa cộng tuyến gây sai lệch các ước lượng hồi quy. Xem thêm bài viết Đa cộng tuyến: Nguyên nhân, dấu hiệu nhận biết và cách khắc phục.
Cụ thể trong ví dụ ở bảng trên, Hệ số VIF của các biến độc lập đều nhỏ hơn 10, trong trường hợp này thậm chí nhỏ hơn 2, do vậy dữ liệu không vi phạm giả định đa cộng tuyến.
Từ các hệ số hồi quy, chúng ta xây dựng được hai phương trình hồi quy chuẩn hóa và chưa chuẩn hóa theo thứ tự như sau:
Y = 0.322*F_LD + 0.288*F_CV + 0.096*F_TL + 0.076*F_DT + 0.421*F_DK + ε
Y= -0.475 + 0.267*F_LD + 0.259*F_CV + 0.084*F_TL + 0.066*F_DT + 0.393*F_DK + ε
Khi viết phương trình hồi quy, lưu ý rằng:
- Không đưa biến độc lập không có ý nghĩa thống kê vào phương trình.
- Nếu biến độc lập có hệ số hồi quy âm, chúng ta sẽ viết dấu trừ trước hệ số hồi quy trong phương trình.
- Nhìn vào phương trình chúng ta sẽ có thể xác định ngay được biến độc lập nào tác động mạnh nhất, mạnh thứ hai,…, yếu nhất lên biến phụ thuộc.
- Luôn có phần dư ε cuối phương trình hồi quy dù là phương trình chuẩn hóa hay chưa chuẩn hóa.
4. Đánh giá giả định hồi quy qua 3 biểu đồ
4.1 Biểu đồ tần số phần dư chuẩn hóa Histogram
Phần dư có thể không tuân theo phân phối chuẩn vì những lý do như: sử dụng sai mô hình, phương sai không phải là hằng số, số lượng các phần dư không đủ nhiều để phân tích… Vì vậy, chúng ta cần thực hiện nhiều cách khảo sát khác nhau. Một cách khảo sát đơn giản nhất là xây dựng biểu đồ tần số của các phần dư Histogram ngay dưới đây. Một cách khác nữa là căn cứ vào biểu đồ P-P Plot ở mục sau.
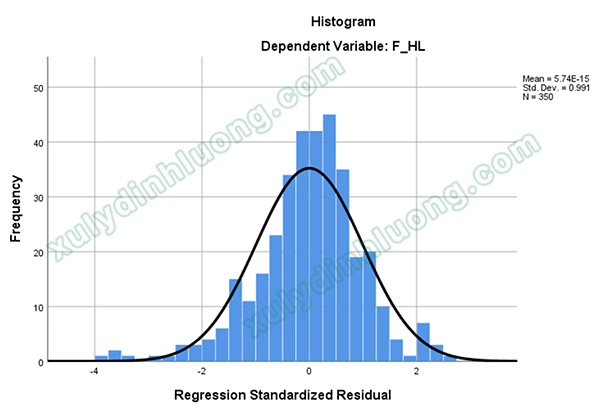
Đối với biểu đồ Histogram, nếu giá trị trung bình Mean gần bằng 0, độ lệch chuẩn Std. Dev gần bằng 1, các cột giá trị phần dư phân bố theo dạng hình chuông, ta có thể khẳng định phân phối là xấp xỉ chuẩn, giả định phân phối chuẩn của phần dư không bị vi phạm. Cụ thể trong ảnh trên, Mean = 5.74E-15 = 5.74 * 10-15 = 0.00000… gần bằng 0, độ lệch chuẩn là 0.991 gần bằng 1. Như vậy có thể nói, phân phối phần dư xấp xỉ chuẩn, giả định phân phối chuẩn của phần dư không bị vi phạm.
4.2 Biểu đồ phần dư chuẩn hóa Normal P-P Plot
Ngoài cách kiểm tra bằng biểu đồ Histogram, thì P-P Plot cũng là một dạng biểu đồ được sử dụng phổ biến giúp nhận diện sự vi phạm giả định phần dư chuẩn hóa.
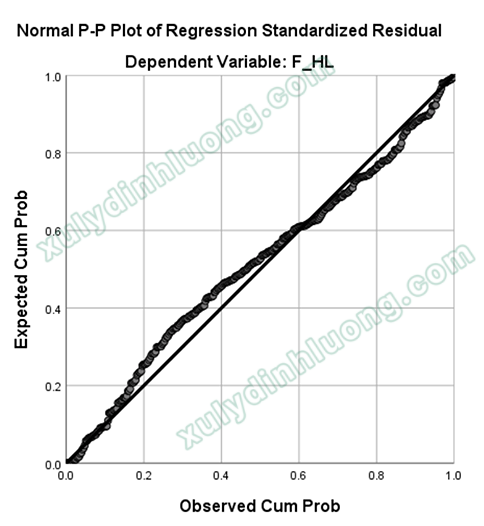
Đối với biểu đồ Normal P-P Plot, nếu các điểm dữ liệu trong phân phối của phần dư bám sát vào đường chéo, phần dư càng có phân phối chuẩn. Nếu các điểm dữ liệu phân bố xa đường chéo, phân phối càng “ít chuẩn”.
Cụ thể với vị dụ trên, các điểm dữ liệu phần dư tập trung khá sát với đường chéo, như vậy, phần dư có phân phối xấp xỉ chuẩn, giả định phân phối chuẩn của phần dư không bị vi phạm.
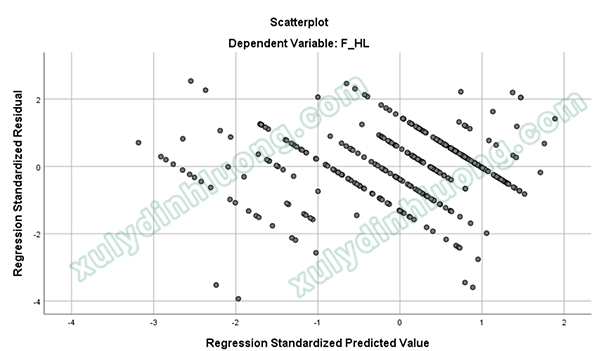
4.3 Biểu đồ Scatter Plot kiểm tra giả định liên hệ tuyến tính